選擇kubenetes的node type
公司的集群一直都在用t2.medium 原因是t2系列中可累積的CPU credit非常實用 詳情可參看 {% post_link aws-t2-medium “AWS中t2.medium的二三事”%} 而且medium的內存(4G)也夠跑一定數量的pod 比較比相當不錯
但最近參考了其他人的做法 把node type從medium轉換成xlarge之後 node的數量大減之餘,價格亦有相當的減少 所以希望在此分享一下心得
為什麼t2.xlarge會比t2.medium好
如果單看價錢的話
t2.xlarge的價錢是t2.medium的4倍
但只有2倍於medium(4個vCPU), cpu credit也沒有去到4倍
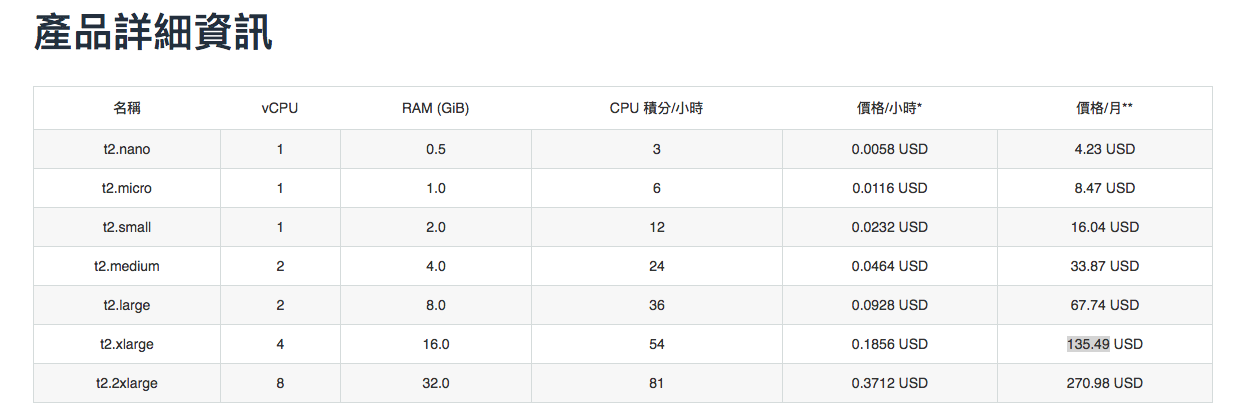
這樣看的話只有內存才算是真的4倍 那為什麼說xlarge會比medium利用率更好呢?
我們首先要看一下kubenetes每個node的一些設定
預設服務
每個node本身都會在其之上跑一些預設的服務
例如kubeproxy

其要求的CPU其實已經佔用了t2.medium的1/20 每開一台新的node,其中最少1/20的CPU已經被系統佔用了 所以要做scaling的預算的話,當中的overhead也應計算在內
Daemonset
如果你的系統有利用到daemonset的話 也會知道每個node都要跟據你的配置去跑一些服務 例如我在集群上跑的一些filebeat跟logrotate 這些東西都會在每個node新增之時”搶去”了一些CPU/內存等的資源
所以每台node新配置的時侯 一定的CPU/內存都會被佔用 而當你的服務器配置選擇比較低的話 其CPU/內存被佔用的比重就相對較高 簡單來說就是overhead比較大 因為一台t2.xlarge相比起四台t2.medium的話 其daemonset/預設服務的比重就直接少了3/4
而且實際情況很多時侯都是memory需求遠比cpu大 cpu需求高的服務我們更應該配置一台r系列的機器專門讓他跑
結論
那如果xlarge比medium好的話 2xlarge會否比xlarge更好? 我會說理論上是 但實際情況你需要分析: 你到底會跑多少個pod? CPU/memory比重是多少? 多少daemon set在跑? 等等的問題 然後再選擇適合你的配置